GestSpoof - FG 2024
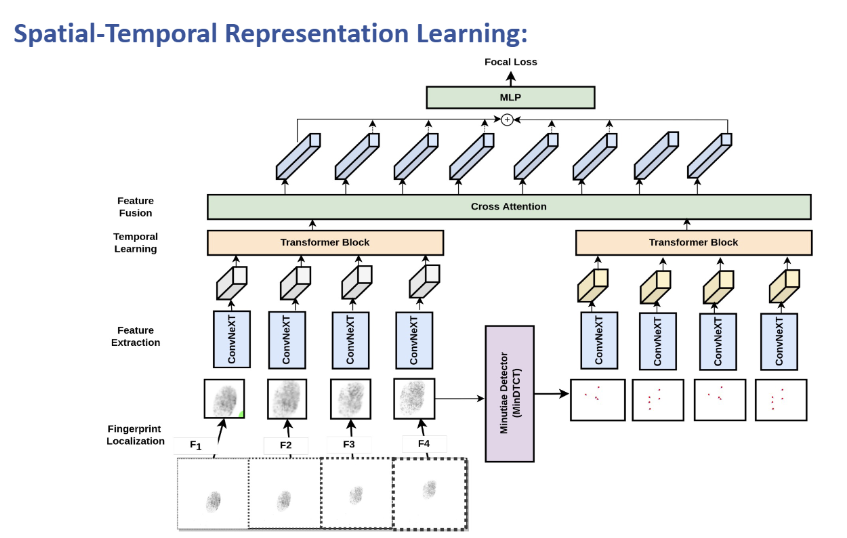
GestSpoof: Gesture Based Spatio-Temporal Representation Learning For Robust Fingerprint Presentation Attack Detection. - FG 2024


My research explores cross-modal world models—AI systems that learn physical properties through prediction discrepancy across modalities.
Learning physical properties through prediction error. When a system predicts the deformation that should accompany applied pressure and observes a mismatch, that error reveals material properties that neither modality encodes alone.
Bidirectional prediction (motion→sound, sound→motion) for material property inference. Zero-shot transfer to material classification without fine-tuning.
Temporal cross-modal prediction for action dynamics. Train models to predict: given current visual state + action, what sound/visual change occurs?
Using cross-modal prediction error as anomaly detector for AI-generated content. Authentic content produces consistent cross-modal signatures; synthetic content fails physical consistency checks.
GestSpoof: Gesture Based Spatio-Temporal Representation Learning For Robust Fingerprint Presentation Attack Detection. - FG 2024

HackerGPT Lite: An AI OSINT and Discovery Tool